近日,搜狗浏览器对外宣布成功实现了12306图形验证码的自动识别,用户借此可以实现全自动抢票的体验。据悉,搜狗浏览器之所以成为市面上首款、也是唯一一款实现了新版12306验证码自动识别的浏览器软件,正是借助了深厚的搜狗识图搜索技术积淀,和强大的大数据处理能力, 打出了“OCR技术+图像分类技术”相结合的组合拳。
与以往的文字、数字验证输入不同,中国铁路客户服务中心(12306)推出的新版图形验证码,要求用户在填写好登录名和密码之后,需要根据文字提示,识别并点击验证图片中的对应选项,只有准确地选取图形验证码才能登陆成功。由于识别难度较大,该方式一经推出,随即引发不少网友吐槽:买火车票前,还得先测智商?
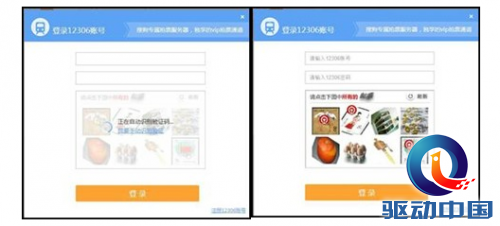
该验证系统推出后,虽然不少抢票软件声称不受影响,但选图仍需用户手动操作完成,事实上新版图形验证码对于抢票软件而言,着实带来了一道难题。通常,该类软件会借助光学字符识别技术(简称:OCR技术),支持自动验证码输入,为用户节省登录时间,提高抢票效率。而对于此前12306的文字、数字验证码来说,OCR技术更为适用。而12306推出新版图形验证码以后,仅凭OCR技术来解决新问题,就显得有些“捉襟见肘”了。
究其原因,首先需要了解OCR其背后的技术原理。通常,OCR识别包括预处理、二值化、去噪、倾斜校正、字符切割、字符识别、后处理等几个步骤。简言之,通过捕捉图像并识别文字,OCR技术使得电脑可以像人一样阅读。
而12306新举措,使得验证码输入由传统相对简单的字母数字识别输入,升级为用户需要根据描述文字从候选多张图片中勾选对应类别的一个选择过程。也就是说,12306新验证码识别由原来的填空题,升级为多选题,由于答案的个数是不确定的,可以说变成了一个不定项选择题。那么,这一问题就不难理解了,原本基于文字就能获得较高识别率的OCR技术,却无法解决候选图片的类别判定,因此就不能破解新版图形验证码。
针对这一难题,搜狗识图搜索率先提出解决方案,打出“OCR技术+图像分类技术”相结合的组合拳,加之以搜狗深度学习技术和大数据分析处理功力,实现了对12306新版图形验证码的自动识别。
在OCR技术的基础上,搜狗识图搜索更进一步,借用了图像分类的思想,首先将经过变形处理的描述文字图像通过OCR技术识别成文本,再通过图像分类技术,对于多张候选图像识别出其分类信息,然后将文本和分类信息进行自动匹配,从而实现验证码的自动识别过程。这样,凭借“OCR技术+图像分类”这套组合拳,搜狗识图搜索就完成了图像识别最为关键的第一步,有效解决了OCR技术无法实现图像识别的问题。
当然,在初步识别图像的基础上,想要准确地选取图形验证码,还需要提高识别精度。目前,搜狗识图搜索对于大部分的12306图形验证码能够实现自动破解,其图像识别精度在该技术领域,已经达到了国内领先水平。
而取得这一成绩的背后,依靠的正是搜狗深度学习技术和大数据积累。目前,伴随互联网科技高速发展,“深度学习”这一被机器学习大师Hinton等人于2006年提出的新概念,其覆盖领域愈来愈广泛,它通过多层次的学习而得到对于原始数据的不同抽象层度的表示,进而提高分类和预测等任务的准确性。此次,搜狗识图搜索成功将其应用于图像识别领域,通过模拟人认知图片的过程,多层次地模拟和学习,大幅提高了图片分类和识别的准确性。截至目前,搜狗深度学习技术已经积累千万量级的模拟训练数据,达到了行业领先水平。
另一方面,搜狗面向全网图像标注而积累的大数据,也同样起到了非常重要的作用。如果说,深度学习技术是急先锋的角色,那么大数据则是充实补给的后方阵地,对于深度学习而言,需要大量数据,正如康奈尔大学创意机器人实验室主任胡迪.利普森所言,深度学习极度“数据饥渴”,如果它们得到越多的数据,就学习得越快越好。”目前,搜狗全网图像标数据库已经沉淀了数千万量级的数据,而这也为搜狗图像识别精度大幅提升奠定了坚持基础,并使其实现图形验证码识别真正成为可能。





















































